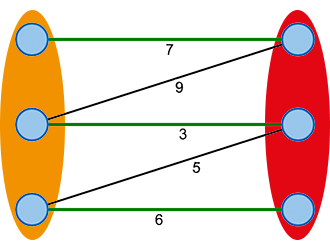
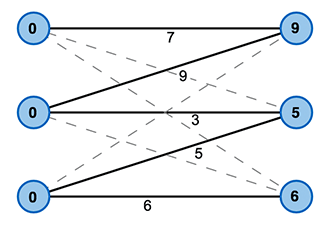
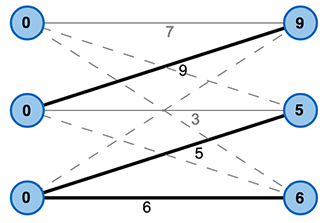
Wir erweitern das das Beispiel einer Zuordnung von Studenten zu passenden Arbeitsstellen durch die Einführung einer Präferenz. Es wird nun eine Zuordnung gesucht, die möglichst die Präferenzen jeden Studenten erfüllt bzw. maximiert.
In der Mathematik ist das Finden von Matchings zwischen Elementen unterschiedlicher Klassen ein häufig auftretendes Problem. In diesem Fall betrachten wir gewichtete Matchingprobleme, d.h. wir suchen Matchings mit optimalen Kantengewichten.
Die hier vorgestellte Ungarische Methode findet dann optimale Matchings in bipartiten Graphen.
Auf welchem Graph soll der Algorithmus ausgeführt werden?
Nimm ein fertiges Beispiel!
Ändere den Graphen nach deinen Vorstellungen:
Um einen Knoten in einer Partition zu erstellen, mache einen Doppelklick in der Nähe dieser Partition. In diesem Graph kannst du maximal 8 Knoten in jeder Partition erstellen.
Um eine Kante zu erstellen, klicke zunächst auf den Ausgangsknoten und dann auf den Zielknoten.
Du kannst nur Kanten zwischen verschiedenen Partitionen einfügen. Um die Gewichte der Kanten zu ändern, klicke doppelt auf den mittleren Teil der Kante und gib den Gewichtswert ein.
Im Alltag kann man viele Zuordnungsprobleme finden, die mittels Matchings auf bipartiten Graphen modelliert werden könnnen. Hier möchten wir uns speziell mit gewichteten Zuordnungsproblemen beschäftigen.
Als Beispiel betrachten wir folgende Problemstellung: Ein Unternehmer hat in seinem Betrieb eine Menge von Aufgaben, die bearbeitet werden müssen. Seine Mitarbeiter sind aufgrund verschiedener Qualifikationen aber nicht alle gleichermaßen für jede Aufgabe geeignet. Das bedeutet, dass alle Mitarbeiter bei der Bearbeitung der Aufgaben jeweils unterschiedliche Effizienzsgrade aufweisen. Weil der Unternehmer möglichst effizient wirtschaften möchte, muss er die Aufgaben so verteilen, dass der Effizienzgrad pro Aufgabe möglichst maximal ist.
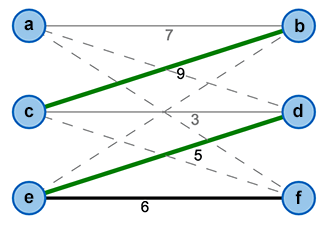
Wir können dieses Problem als bipartiten Graphen mit Knotenmengen \(X\) (orange) für die Mitarbeiter und \(Y\) (rot) für die Aufgaben darstellen (vgl. Bild 1). In folgenden Darstellungen werden wir die Knotenmengen nicht erneut kennzeichnen. Die gewichteten Kanten zwischen den Mengen definieren dann die Anzahl der Stunden, die ein Mitarbeiter \(x\) für Aufgabe \(y\) benötigt. Jetzt gilt es ein perfektes Matching zu finden, bei dem die Summe aller Kantengewichte maximal ist.
Die Ungarische Methode
Das Problem kann mittels der Ungarischen Methode gelöst werden, die 1955 von Harold W. Kuhn auf Grundlage der Ideen zweier ungarische Mathematiker (Dénes Kőnig und Jenő Egerváry) entwickelt wurde. Der Algorithmus wurde später von James Munkres verbessert und basiert auf einem zentralen Theorem für dessen Verständnis wir aber ein paar Begriffe benötigen:
Markierung
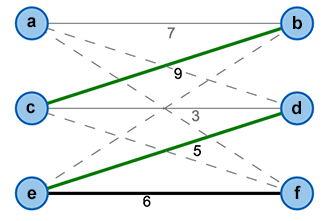
Wir führen eine einfache Hilfsfunktion oder Markierung \(l\) ein, die jedem Knoten im Graph eine reelle Zahl so zuordnet, dass die Summe der Markierungen zweier Knoten mindestens so groß ist, wie das Kantengewicht \(w\) der Kante, die diese Knoten verbindet (vgl. Bild 2).
\(l(x) + l(y) \ge w(x, y)\)
Gleichheitsgraph
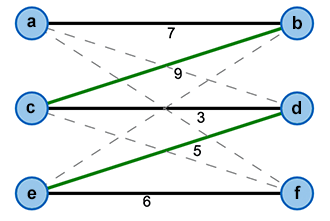
Mittels der Markierungen können wir einen Gleichheitsgraph \(G_l = (V, E_l)\) definieren der alle Knoten aus unserem Ausgangsgraph besitzt. Die Kantenmenge enthält jedoch nur die Kanten, deren Gewicht genau der Summe der Markierungen ihrer Knoten entspricht (vgl. Bild 3).
Nun zu dem oben angesprochenem Theorem. Das Kuhn-Munkres-Theorem besagt, dass wenn man ein perfektes Matching im Gleichheitsgraph findet, dieses im Ausgangsgraph maximal ist. Das Problem des optimalen Matchings kann man damit also auf das Finden eines perfekten Matchings im Gleichheitsgraph reduzieren.
Bevor wir nun zum eigentlichen Algorithmus kommen, hier noch ein paar Hinweise:
Die Ungarische Methode in der hier beschriebenen Form findet maximale Matchings, also Matchings mit möglichst hohen Kantengewichten. Das bedeutet, dass wir das zu Beginn geschilderte Problem umformen müssen. Dazu kann man die Kantengewichte durch einen Vorzeichenwechsel "spiegeln", d.h. aus \(w(x,y)\) macht man \(-w(x,y)\).
Außerdem muss der bipartite Graph, auf den wir den Algorithmus anwenden vollständig sein. Das heißt, es muss gleich viele Knoten in \(X\) und \(Y\) geben und von jedem Knoten einer Partition müssen Kanten zu jedem Knoten der anderen Partition führen. In unserem Beispiel wäre dies nicht der Fall, wenn ein Mitarbeiter eine Aufgabe gar nicht bearbeiten kann. In diesem Fall fügt man neutrale Knoten und Kanten mit Kantengewicht \(0\) ein, sodass der Graph vollständig wird. Sofern die hinzugefügten neutralen Elemente nach Ausführung des Algorithmus im gefundenen Matching enthalten sind, kann man sie einfach wieder entfernen.
Der Ablauf des Algorithmus
Das Finden eines perfekten Matchings im Gleichheitsgraph geschieht schrittweise. Der Algorithmus beginnt mit einem leeren Matching und versucht dieses in jedem Schritt zu verbessern, bis es perfekt ist.
Zu Beginn bestimmt der Algorithmus für alle Knoten eine Markierung. Die Markierung eines Knoten aus \(X\) entspricht dem Gewicht seiner größten Kante und \(0\) für einen Knoten aus \(Y\). Mittels der Markierungen bestimmt der Algorithmus dann einen Gleichheitsgraph. Für den weiteren Ablauf definieren wir zunächst weitere Begriffe:
Alternierende und augmentierende Pfade
Wir sagen, ein Knoten wurde gematcht, wenn er eine Kante besitzt, die im aktuellen Matching enthalten ist. Ansonsten nennen wir ihn frei (vgl. Bild 4).
Ein alternierender Pfad ist eine Abfolge von Kanten, bei dem die Kanten abwechselnd im Matching \(M\) enthalten und nicht enthalten \(E \setminus M\) sind (vgl. Bild 5). Ein alternierender Pfad ist zusätzlich augmentierend, wenn Anfangs- und Endknoten beide frei sind (vgl. Bild 6).
Um das bestehende noch leere Matching zu verbessern, sucht sich der Algorithmus einen Knoten aus \(X\), der noch keinen Matchingpartner besitzt. Ausgehend von diesem, versucht der Algorithmus einen augmentierenden Pfad zu finden. Dazu baut der Algorithmus schrittweise einen alternierenden Pfad, solange bis dieser augmentierend wird oder es keine weitere Kante mehr gibt. Die dabei besuchten Knoten teilen wir in die Mengen \(S\) für besuchte Knoten aus \(X\) und die Menge \(T\) für besuchte Knoten aus \(Y\) ein.
Es lässt sich nicht immer ein augmentierender Pfad finden. Dann muss der Algorithmus die Markierungen verbessern. Die Verbesserung muss so erfolgen, dass das aktuelle Matching im Gleichheitsgraph enthalten bleibt. Außerdem muss der Gleichheitsgraph durch neue Kanten so erweitert werden, dass ein neuer alternierender Pfad konstruiert werden kann. Dies geschieht, indem zunächst ein \(\Delta\) bestimmt wird. Der Algorithmus betrachtet alle Paare aus besuchten Knoten \(s \in S\) und unbesuchten Knoten \(y \in Y \setminus T\) und bildet das Minimum aus der Summe ihrer Markierungen abzüglich des Gewichts der Kante zwischen beiden Knoten.
\(\Delta = \min\limits_{s \in S\ \wedge\ y \in Y \setminus T}\{l(s) + l(y) - w(s,y)\}\)
Mittels \(\Delta\) kann man nun die Markierungen aller Knoten anpassen. Danach bestimmt der Algorithmus einen neuen Gleichheitsgraph und sucht erneut nach einem augmentierenden Pfad.
\(\begin{equation}
l^\prime(v) =
\begin{cases}
l(v) - \Delta & v \in S\\
l(v) + \Delta & v \in T \\
l(v) & sonst
\end{cases}
\end{equation}\)
Wenn der Algorithmus einen augmentierenden Pfad findet, verbessert er das Matching, indem er die Kanten des Pfades, die nicht in dem Matching enthalten sind, dem Matching hinzufügt und die Kanten des Pfades, die im Matching enthalten sind, entfernt. Dieses Vorgehen wird wiederholt, bis jeder Knoten einen Matchingpartner hat und das Matching so perfekt ist. Nach dem o.g. Theorem ist das bestimmte Matching dann bezüglich der Kantengewichte ein maximales Matching.
Was nun?
Einen Graph erstellen und den Algorithmus durchspielen
Eingabe: Vollständiger gewichteter bipartiter Graph \(G=(V,E)\) Ausgabe: Bezüglich Kantengewichte optimales Matching \(M \subseteq E\) als Liste von Kanten
BEGIN
Initialisiere Markierungen
Konstruiere Gleichheitsgraph
WHILE Matching nicht optimal DO
Finde freien Knoten als Wurzel eines alternierenden Pfades
WHILE Pfad ist nicht augmentierend DO
Konstruiere alternierenden Pfad in Gleichheitsgraph
IF Kein alternierender Pfad gefunden
THEN Verbessere Markierungen und konstruiere neuen Gleichheitsgraph
END
Verbessere Matching
END
END
Wie schnell ist der Algorithmus?
Geschwindigkeit von Algorithmen
Die Geschwindigkeit von Algorithmen wird üblicherweise in der Anzahl an Einzelschritten gemessen, die der Algorithmus bei der Ausführung benötigt.
Einzelschritte sind beispielsweise:
Zuweisungen – Weise Knoten 1 den Wert 20 zu.
Vergleiche – Ist 20 größer als 23?
Vergleich und Zuweisung – Falls 20 größer als 15 ist, setze Variable n auf 20.
Einfache Arithmetische Operationen – Was ist 5 + 5 ?
Da es sehr schwierig sein kann, diese Einzelschritte exakt zu zählen, möchte man nur die ungefähre Größenordnung der Anzahl Schritte wissen. Man spricht auch von der Laufzeit des Algorithmus. Meistens ist es besonders interessant, zu wissen, wie die Geschwindigkeit des Algorithmus von der Größe der Eingabe (hier: Anzahl Kanten und Knoten im Graph) abhängt.
Laufzeit der Ungarischen Methode
Zur Implementierung der Ungarischen Methode gibt es mehrere Varianten, die sich in ihrer Laufzeit unterscheiden. Wir betrachten hier die Variante mit der kürzesten Laufzeit.
Dazu gehen wir von einem vollständig bipartitem Graphen \(G = (V, E)\) mit \(V = X \cup Y \land X \cap Y = \emptyset\) und einem leeren initialen Matching \(M\) aus. Zur Komplexitätsbestimmung definieren wir außerdem \(|V| = n, |X| = n_1, |Y| = n_2\).
Zu Beginn wird der Graph mit neutralen Kanten ergänzt und es wird ein initales Matching bestimmt. Dazu müssen alle Kanten betrachtet werden. In vollständigen bipartien Graphen sind das \(O(n_1 * n_2)\).
Der Algorithmus versucht dann, in jedem Durchgang das Matching um einen Knoten zu ergänzen, d.h. er benötigt maximal \(n\) Durchgänge. Pro Durchgang werden mehrere Berechnungen durchgeführt:
Zur Bestimmung des Gleichheitsgraphs müssen ebenfalls alle Kanten betrachtet werden: \(O(n_1 * n_2)\).
Das Finden einer neuen Wurzel benötigt im schlechtesten Fall \(O(n)\).
Zur Konstruktion eines augmentierenden Pfades werden von der Wurzel ausgehend alle Kanten des Gleichheitsgraphs betrachtet. Dieser enthält im ungünstigsten Fall alle Kanten. Das heißt man erhält hier wieder eine Komplexität von \(O(n_1 * n_2)\).
Der augmentierende Pfad beseitzt maximal die Länge \(n\). Daher benötigt das anschließende Austauschen der Kanten zum verbessern des Matchings \(O(n)\) Schritte.
Die Überprüfung, ob das gefundene Matching perfekt ist, kann durch einen einfachen Vergleich der Anzahl der Kanten bewerkstelligt werden: \(O(1)\).
Die signifikateste Berechnung tritt auf, wenn kein augmentierender Pfad gefunden werden kann. Dann muss ein neuer Gleichheitsgraphs durch Anpassung der Markierungen und Berechnung eines Deltas \(\Delta\) bestimmt werden. Durch die Bestimmung eines neuen Gleichheitsgraph besteht jedoch keine Garantie, dass ein augmentierender Pfad konstruiert werden kann. Insgesamt können dem Gleichheitsgraph durch Verbesserungen der Markierungen aber nur \(O(n)\) Kanten hinzugefügt werden. Dieser Vorgang besitzt bei trivialer Implementierung eine Laufzeit von \(O(n^4)\). Durch geschicktes Zwischenspeichern einzelner Werte kann die Berechnung des Deltas aber auf \(O(n^2)\) reduziert werden.
Insgesamt besitzt der Algorithmus damit eine kubische Laufzeit von \(O(n^3)\).
Wie beweist man, dass der Algorithmus stets ein korrektes Ergebnis berechnet?
Maßgeblich für die Korrektheit des Algorithmus ist das Kuhn-Munkres-Theorem. Es besagt, dass perfekte Matchings in einem Gleichheitsgraph im Ursprungsgraph optimal sind, d.h. maximales Gewicht haben.
Formaler Beweis
Wir gehen von zulässigen Markierungen \(l: V \to \mathbb{R}\), einem beliebigen perfekten Matching \(M' \subseteq E\) und einem optimalen Matching \(M \subseteq E\) mit maximalem Gewicht \(w(M)\) aus.
\(
\begin{align}
w(M')
&= \sum\limits_{(x,y) \in M'} w(x,y) &&\text{(Gesamtgewicht ist gleich der Summe der Kantengewichte)}
\\ &\le \sum\limits_{(x,y) \in M'} (l(x) + l(y)) &&\text{(Einsetzen der Markierungs Formel)}
\\ &= \sum\limits_{v \in V} l(v) &&\text{(Da M' perfekt, ist jede Markierung genau einmal in der Summe enthalten)}
\\ &= \sum\limits_{(x,y) \in M} (l(x) + l(y)) &&\text{(Da M auch perfekt, gilt das gleiche)}
\\ &= \sum\limits_{(x,y) \in M} w(x,y) &&\text{(Alle Kanten aus M sind im Gleichheitsgraph enthalten)}
\\ &= w(M) && \square
\end{align}
\)
Wo finde ich noch mehr Informationen zu Graphalgorithmen?
Ein letzter Hinweis zum Ziel und Inhalt dieser Seite und zu Zitationen
Der Lehrstuhl M9 der TU München beschäftigt sich mit diskreter Mathematik, angewandter Geometrie und der mathematischen Optimierung von angewandten Problemen. Die hier dargestellten Algorithmen sind sehr grundlegende Beispiele für Verfahren der diskreten Mathematik (die tägliche Forschung des Lehrstuhls geht weit darüber hinaus). Die vorliegenden Seiten sollen SchülerInnen und Studierenden dabei helfen, diese auch im realen Leben sehr wichtigen Verfahren (besser) zu verstehen und durch Ausprobieren zu durchdringen. Aus diesem Grund konzentriert sich die Darstellung bewusst auf die Ideen der Algorithmen, und präsentiert diese oftmals unter weitestgehendem Verzicht auf mathematische Notation.
Bitte beachten Sie, dass diese Seiten im Rahmen von studentischen Arbeiten unter Betreuung des Lehrstuhls M9 erstellt wurden. Den dabei entstandenen Code und die zugehörige Darstellung können wir nur punktuell überprüfen, und können deshalb keine Garantie für die vollständige Korrektheit der Seiten und der implementierten Algorithmen übernehmen.
Selbstverständlich freuen wir uns über jegliches (auch kritisches) Feedback bezüglich der Anwendungen sowie eventuellen Ungenauigkeiten und Fehlern der Darstellung und der Algorithmen. Bitte nutzen Sie hierzu den Anregungen-Link, welcher auch rechts in der Fußleiste zu finden ist.
Um diese Seite zu zitieren, nutze bitte die folgenden Angaben:
Titel: Die Ungarische Methode
Autoren: Mark J. Becker, Wolfgang F. Riedl, Aleksejs Voroncovs; Technische Universität München